原文地址¶
1.基础¶
在引入IO模型前,先对io等待时某一段数据的"经历"做一番解释。如图:
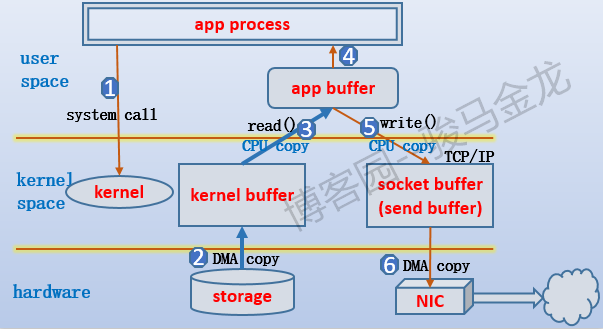
当某个程序或已存在的进程/线程(后文将不加区分的只认为是进程)需要某段数据时,它只能在用户空间中属于它自己的内存中访问、修改,这段内存暂且称之为app buffer。假设需要的数据在磁盘上,那么进程首先得发起相关系统调用,通知内核去加载磁盘上的文件。但正常情况下,数据只能加载到内核的缓冲区,暂且称之为kernel buffer。数据加载到kernel buffer之后,还需将数据复制到app buffer。到了这里,进程就可以对数据进行访问、修改了。
现在有几个需要说明的问题。
(1).为什么不能直接将数据加载到app buffer呢 ?
实际上是可以的,有些程序或者硬件为了提高效率和性能,可以实现内核旁路的功能,避过内核的参与,直接在存储设备和app buffer之间进行数据传输,例如RDMA技术就需要实现这样的内核旁路功能。
但是,最普通也是绝大多数的情况下,为了安全和稳定性,数据必须先拷入内核空间的kernel buffer,再复制到app buffer,以防止进程串进内核空间进行破坏。
(2).上面提到的数据几次拷贝过程,拷贝方式是一样的吗 ?
不一样。现在的存储设备(包括网卡)基本上都支持DMA操作。什么是DMA(direct memory access,直接内存访问)?简单地说,就是内存和设备之间的数据交互可以直接传输,不再需要计算机的CPU参与,而是通过硬件上的芯片(可以简单地认为是一个小cpu)进行控制。
假设,存储设备不支持DMA,那么数据在内存和存储设备之间的传输,必须由内核线程占用CPU去完成数据拷贝(比如网卡不支持DMA时,内核负责将数据从网卡拷贝到kernel buffer)。而DMA就释放了计算机的CPU,让它可以去处理其他任务,DMA也释放了从用户进程切换到内核的过程,从而避免了用户进程在这个拷贝阶段被阻塞。
再说kernel buffer和app buffer之间的复制方式,这是两段内存空间的数据传输,只能由内核占用CPU来完成拷贝。
所以,在加载硬盘数据到kernel buffer的过程是DMA拷贝方式,而从kernel buffer到app buffer的过程是CPU参与的拷贝方式。
(3).如果数据要通过TCP连接传输出去要怎么办 ?
例如,web服务对客户端的响应数据,需要通过TCP连接传输给客户端。
TCP/IP协议栈维护着两个缓冲区:send buffer和recv buffer,它们合称为socket buffer。需要通过TCP连接传输出去的数据,需要先复制到send buffer,再复制给网卡通过网络传输出去。如果通过TCP连接接收到数据,数据首先通过网卡进入recv buffer,再被复制到用户空间的app buffer。
同样,在数据复制到send buffer或从recv buffer复制到app buffer时,是内核占用CPU来完成的数据拷贝。从send buffer复制到网卡或从网卡复制到recv buffer时,是DMA方式的拷贝,这个阶段不需要切换到内核,也不需要计算机自身的CPU。
如下图所示,是通过TCP连接传输数据时的过程。
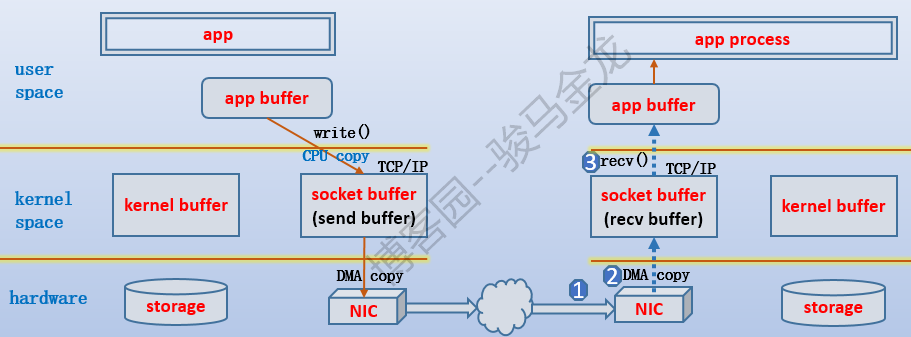
(4).网络数据一定要从kernel buffer复制到app buffer再复制到send buffer吗 ?
不是。如果进程不需要修改数据,就直接发送给TCP连接的另一端,可以不用从kernel buffer复制到app buffer,而是直接复制到send buffer。这就是零复制 技术。
例如,如果httpd进程不需要访问和修改任何数据,那么将数据原原本本地复制到app buffer再原原本本地复制到send buffer然后传输出去的过程中,从kernel buffer复制到app buffer的过程是可以省略的。使用零复制技术,就可以减少一次拷贝过程,提升效率。
当然,实现零复制技术的方法有多种,见我的另一篇结束零复制的文章:零复制(zero copy)技术技术")。
以下是以httpd进程处理文件类请求时比较完整的数据操作流程。
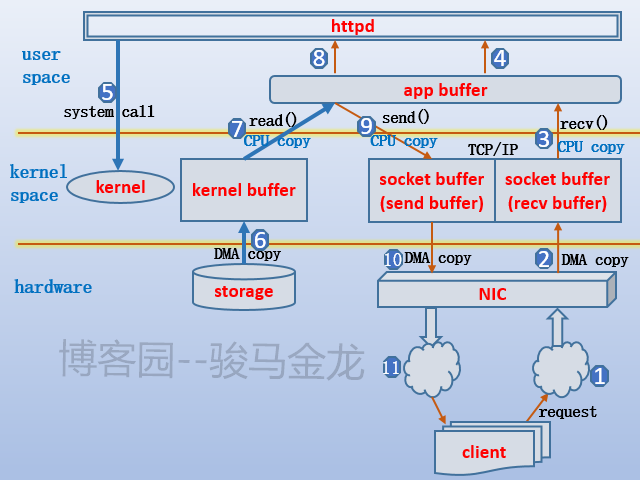
大致解释下:客户端发起对某个文件的请求,通过TCP连接,请求数据进入TCP的recv buffer,再通过recv()函数将数据读入到app buffer,此时httpd工作进程对数据进行一番解析,知道请求的是某个文件,于是发起read系统调用,于是内核加载该文件,数据从磁盘复制到kernel buffer再复制到app buffer,此时httpd就要开始构建响应数据了,可能会对数据进行一番修改,例如在响应首部中加一个字段,最后将修改或未修改的数据复制(例如send()函数)到send buffer中,再通过TCP连接传输给客户端。
2. I/O模型¶
所谓的IO模型,描述的是出现I/O等待时进程的状态以及处理数据的方式。围绕着进程的状态、数据准备到kernel buffer再到app buffer的两个阶段展开。其中数据复制到kernel buffer的过程称为数据准备 阶段,数据从kernel buffer复制到app buffer的过程称为数据复制 阶段。请记住这两个概念,后面描述I/O模型时会一直用这两个概念。
本文某些地方以httpd进程的TCP连接方式处理本地文件为例,请无视httpd是否真的实现了如此、那般的功能,也请无视TCP连接处理数据的细节,这里仅仅只是作为方便解释的示例而已。
再次说明,从硬件设备到内存的数据传输过程是不需要CPU参与的,而内存间传输数据是需要内核线程占用CPU来参与的。
2.1 Blocking I/O模型¶
如图:
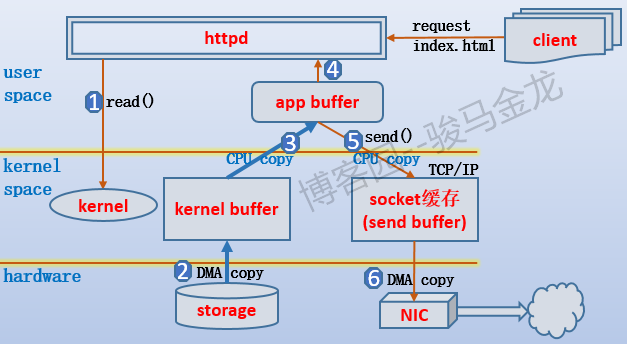
假设客户端发起index.html的文件请求,httpd需要将index.html的数据从磁盘中加载到自己的httpd app buffer中,然后复制到send buffer中发送出去。
但是在httpd想要加载index.html时,它首先检查自己的app buffer中是否有index.html对应的数据,没有就发起系统调用让内核去加载数据,例如read(),内核会先检查自己的kernel buffer中是否有index.html对应的数据,如果没有,则从磁盘中加载,然后将数据准备到kernel buffer,再复制到app buffer中,最后被httpd进程处理。
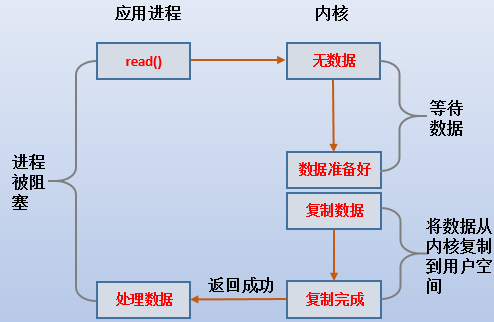
如果使用Blocking I/O模型:
(1).当设置为blocking i/o模型,1到3都是被阻塞的。
(2).只有当数据复制到app buffer完成后,或者发生了错误,httpd才被唤醒处理它app buffer中的数据。
(3).cpu会经过两次上下文切换:用户空间到内核空间再到用户空间,第一次是发起系统调用的切换,第二次是内核将数据拷贝到app buffer完成后的切换。
(4).由于2阶段的拷贝是不需要CPU参与的,所以在2阶段准备数据的过程中,cpu可以去处理其它进程的任务。
(5).3阶段的数据复制需要CPU参与,将httpd阻塞。
(6).这是最省事、最简单的IO模式。
如下图:
2.1 Non-Blocking I/O模型¶
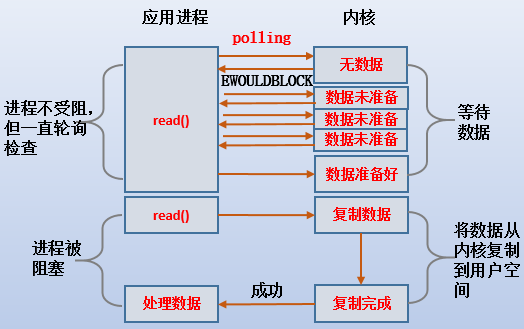
(1).当设置为non-blocking时,httpd第一次发起系统调用(如read())后,立即返回一个错误值EWOULDBLOCK,而不是让httpd进入睡眠状态。UNP中也正是这么描述的。
When we set a socket to be nonblocking, we are telling the kernel "when an I/O operation that I request cannot be completed without putting the process to sleep, do not put the process to sleep, but return an error instead.
(2).虽然read()立即返回了,但httpd还要不断地去发送read()检查内核:数据是否已经成功拷贝到kernel buffer了?这称为轮询(polling)。每次轮询时,只要内核没有把数据准备好,read()就返回错误信息EWOULDBLOCK。
(3).直到kernel buffer中数据准备完成,再去轮询时不再返回EWOULDBLOCK,而是将httpd阻塞,以等待数据复制到app buffer。
(4).httpd在1到2阶段不被阻塞,但是会不断去发送read()轮询。在3被阻塞,将cpu交给内核把数据copy到app buffer。
如下图:
2.3 I/O Multiplexing模型¶
称为多路IO模型或IO复用,意思是可以检查多个IO等待的状态。有三种IO复用模型:select、poll和epoll。其实它们都是一种函数,用于监控指定文件描述符的数据是否就绪。
就绪指的是对某个系统调用不再阻塞了,可以直接执行IO。例如对于read()来说,数据准备好了就是就绪状态,此时read()可以直接去读取数据且能立即读取到数据,对write()来说,就是有空间可以写入数据了(比如缓冲区未满),此时write()可以直接写入。
就绪种类包括是否可读、是否可写以及是否异常,其中可读条件中就包括了数据是否准备好,也即数据是否已经在kernel buffer中。当就绪之后,将通知进程,进程再发送对数据操作的系统调用,如read()。
所以,这三个函数仅仅只是处理了数据是否准备好以及如何通知进程的问题。可以将这几个函数结合阻塞和非阻塞IO模式使用,但通常IO复用都会结合非阻塞IO模式。
select()和poll()差不多,它们的监控和通知手段是类似的,只不过poll()要更聪明一点,某些时候效率也更高些,此处仅以select()监控单个文件请求为例简单介绍IO复用,至于更具体的、监控多个文件以及epoll的方式,在本文的最后专门解释。
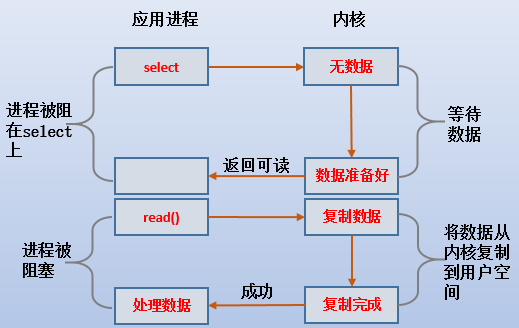
(1).当想要加载某个文件时,假如httpd要发起read()系统调用,如果是阻塞或者非阻塞情形,那么read()会根据数据是否准备好而决定是否返回。是否可以主动去监控这个数据是否准备到了kernel buffer中呢,亦或者是否可以监控send buffer中是否有新数据进入呢?这就是select()/poll()/epoll的作用。
(2).当使用select()时,进程被select()所『阻塞』,之所以阻塞要加上引号,是因为select()有时间间隔选项可用控制阻塞时长,如果该选项设置为0,则select不阻塞而是立即返回,还可以设置为永久阻塞。
(3).当select()的监控对象就绪时,httpd进程通过轮询判断知道可以执行read()了,于是httpd再发起read()系统调用,此时数据会从kernel buffer复制到app buffer中并read()成功。
(4).httpd发起read()系统调用后切换到内核,由内核占用CPU来复制数据到app buffer,所以httpd进程被阻塞。
上面的描述可能还太过抽象,这里用shell伪代码来简单描述select()的工作方式(细节并非准确,但易于理解)。假设有一个select命令,作用和select()函数相同。伪代码如下:
# select监控指定的文件描述符,并返回已就绪的描述符数量给x
# 进程将阻塞在select命令上,直到select返回
x=$(select fd1 fd2 fd3)
# 如果x大于0,说明有文件描述符数据就绪,于是遍历所有fd,
# 并分别使用read去读取这些fd,但并不知道具体是哪个fd已
# 就绪,所以read时最好是非阻塞的读取,否则read每一个未
# 就绪的fd时都会阻塞
if [ x -gt 0 ];then
for fd in fd1 fd2 fd3;do
read -t 0 -u $fd # read操作最好是非阻塞的
done
fi
所以,在使用IO复用模型时,真正的IO操作(比如read)最好是非阻塞方式的,但并非必须。比如只监控一个文件描述符时,select能返回意味着这个文件描述符一定是就绪的(select还有其它返回值,但这里不考虑其它返回值。
IO多路复用时,模型如图:
select/poll的性能问题¶
select()/poll()的性能会随着监控的文件描述符数量增多而快速下降。其原因是多方面的。
其中一个原因是它们所监控的文件描述符会以某种数据结构全部传送给内核,让内核负责监控这些文件描述符,当内核发现某个文件描述符已经就绪时,会修改数据结构,然后将修改后的数据结构传回给进程。所以涉及了两次数据传输的过程。
对于select()来说,每次传递的数据结构的大小是固定的,都是1024个描述符的大小。对于poll()来说,只会传递被监控的文件描述符,所以文件描述符少的时候,poll()的性能是可以的,此外poll()可以超出1024个文件描述符的监控数量限制,但随着描述符数量的增多,来回传递的数据量也是非常大的。
基于这方面的性能考虑,更建议使用信号驱动IO或epoll模型,它们都是直接告诉内核要监控哪些文件描述符,内核会以合适的数据结构安排这些待监控的文件描述符(如epoll,内核采用红黑树的方式),换句话说,它们不会传递一大片的文件描述符数据结构,效率更高。
使用IO复用还有很多细节,本文在此仅只是对其作最基本的功能性描述,在本文末还会多做一些扩展,至于更多的内容需自行了解。
2.4 Signal-driven I/O模型¶
即信号驱动IO模型。当文件描述符上设置了O_ASYNC标记时,就表示该文件描述符是信号驱动的IO。
注:可能你觉得O_ASYNC应该表示的是异步IO,但并非如此。
在历史上,信号驱动IO也称为异步IO,比如这个标记就暗含了这一点历史。
如今常说的术语【异步】,是由POSIX AIO规范所提供的功能,这个异步表示某进程发起IO操作时,立即返回,当IO完成或有错误时,该进程会收到通知,于是该进程可以去处理这个通知,比如执行回调函数。
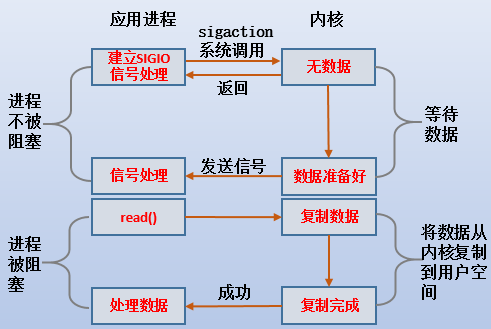
当某个文件描述符使用信号驱动IO模型时,要求进程配置信号SIGIO的信号处理程序,然后进程就可以做其他任何事情。当该文件描述符就绪时,内核会向该进程发送SIGIO信号。该进程收到SIGIO信号后,就会去执行已经配置号的信号处理程序。
通常来说,SIGIO的信号处理程序中会编写read()类的读取代码,这表示在收到SIGIO时在信号处理程序中执行read操作,另一种常见的作法是在SIGIO的信号处理程序中设置某变量标记,然后在外部判断该标记是否为true,如果标记为true,则执行read类的操作。
使用Shell伪代码如下:
# 第一种模式:在信号处理程序中执行IO操作
trap 'read...' SIGIO # 设置SIGIO的信号处理程序
# 然后就可以执行其它任意任务
# 当在执行其它任务过程中,内核发送了SIGIO,进程会
# 立即去执行SIGIO信号处理程序
...other codes...
# 第二种模式:在信号处理程序中设置变量标记,在外部执行IO操作
trap 'a=1' SIGIO
... other codes...
#
while [ $a -eq 1 ];do
read...
done
很明显,使用信号驱动IO模型时,进程对该描述符的读取是被动的,进程不会主动在描述符就绪前执行读取操作。
其实信号驱动IO模型就像是小姐姐在闲逛,小姐姐本没有想过要买什么东西,但如果发现有合适的,也会去买下来,在逛了一段时间后,一件超短裙闪现到小姐姐的视线,小姐姐很喜欢这个款式,于是立即决定买下来。
这里可以做出大胆的推测,***并非所有文件描述符类型都能使用信号驱动的IO模型*** 。如果某文件描述符想要开启信号驱动IO,要求有某个另一端会主动向该描述符发送数据,比如管道、套接字、终端等都符合这种要求。显然,普通文件系统上的文件IO是无法使用信号驱动IO的。**
回到信号驱动IO模型,由于进程没有主动执行IO操作,所以不会阻塞,当数据就绪后,进程收到内核发送的SIGIO信号,进程会去执行SIGIO的信号处理程序,当进程执行read()时,由于数据已经就绪,所以可以直接将数据从kernel buffer复制到app buffer,read()过程中,进程将被阻塞。
注意:sigio信号只是通知了数据就绪,但并不知道有多少数据已经就绪。
如图:
2.5 Asynchronous I/O模型¶
即异步IO模型。
异步IO来自于POSIX AIO规范,它专门提供了能异步IO的读写类函数,如aioread(),aiowrite()等。
使用异步IO函数时,要求指定IO完成时或IO出现错误时的通知方式,通知方式主要分两类:
- 发送指定的信号来通知
- 在另一个线程中执行指定的回调函数
为了帮助理解,这里假设aio_read()的语法如下(真实的语法要复杂的多):
其中nofity_mode允许的值有两种:
- 当notify_mode参数的值为
SIGEV_SIGNAL时,notify_value参数的值为一个信号 - 当notify_mode参数的值为
SIGEV_THREAD,notify_value参数的值为一个函数,这个函数称为回调函数
当使用异步IO函数时,进程不会因为要执行IO操作而阻塞,而是立即返回。
例如,当进程执行异步IO函数aio_read()时,它会请求内核执行具体的IO操作,当数据已经就绪***且从kernel buffer拷贝到app buffer*** 后,内核认为IO操作已经完成,于是内核会根据调用异步IO函数时指定的通知方式来执行对应的操作:**
- 如果通知模式是信号通知方式(SIGEV_SIGNAL),则在IO完成时,内核会向进程发送notify_value指定的信号
- 如果通知模式是信号回调方式(SIGEV_THREAD),则在IO完成时,内核会在一个独立的线程中执行notify_value指定的回调函数
回顾一下信号驱动IO,信号驱动IO要求有另一端主动向文件描述符写入数据,所以它支持像socket、pipe、terminal这类文件描述符,但不支持普通文件IO的文件描述符。
而异步IO则没有这个限制,异步IO操作借助的是那些具有神力的异步函数,只要文件描述符能读写,就能使用异步IO函数来实现异步IO。
所以,异步IO在整个过程中都不会被阻塞。如图:
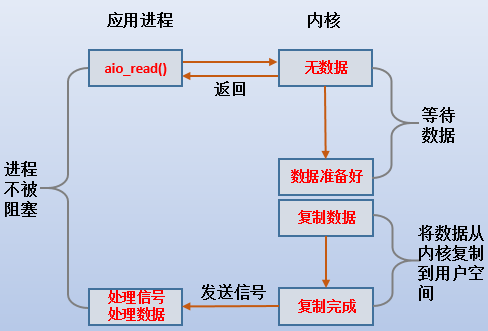
看上去异步很好,但是注意,在复制kernel buffer数据到app buffer中时是需要CPU参与的,这意味着不受阻的进程会和异步调用函数争用CPU。以httpd为例,如果并发量比较大,httpd接入的连接数可能就越多,CPU争用情况就越严重,异步函数返回成功信号的速度就越慢。如果不能很好地处理这个问题,异步IO模型也不一定就好。
2.6 同步IO和异步IO、阻塞和非阻塞的区分¶
阻塞和非阻塞,体现在当前进程是否可执行,是否能获取到CPU。
当阻塞和非阻塞的概念体现在IO模型上:
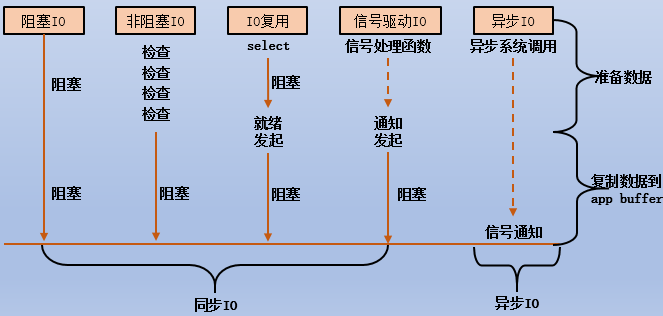
- 阻塞IO:从开始发起IO操作开始就阻塞,直到IO完成才返回,所以进程会立即进入睡眠态
- 非阻塞IO:发起IO操作时,如果当前数据已就绪,则切换到内核态由内核完成数据拷贝(从kernel buffer拷贝到app buffer),此时进程被阻塞,因为它的CPU已经被内核抢走了。如果发起IO操作时数据未就绪,则立即返回而不阻塞,即进程继续享有CPU,可以继续任务。但进程不知道数据何时就绪,所以通常会采用轮循代码(比如while循环)不断判断数据是否就绪,当数据最终就绪后,切换到内核态,进程仍然被阻塞
同步和异步,考虑的是两边数据是否同步(比如kernel buffer和app buffer之间数据是否同步)。同步和异步的区别体现在两边数据尚未完成同步时的行为:
- 同步:在保持两边数据同步的过程中,进程被阻塞,由内核抢占其CPU去完成数据同步,直到两边数据同步,进程才被唤醒
- 异步:在保持两边数据同步的过程中,由内核默默地在后台完成数据同步(如果不理解,可认为是单独开了一个内核线程负责数据同步),内核不会抢占进程的CPU,所以进程自身不被阻塞,当内核完成两端数据同步时,通知进程已同步完成
这里阻塞和非阻塞、同步和异步都是广义的概念,上面所做的解释适用于所有使用这些术语的情况,而不仅仅是本文所专注的IO模型。
回到阻塞、非阻塞、同步、异步的IO模型,再对它们啰嗦啰嗦。
阻塞、非阻塞、IO复用、信号驱动都是同步IO模型。需注意,虽然不同IO模型在加载数据到kernel buffer的数据准备过程中可能阻塞、可能不阻塞,***但kernel buffer才是read()函数读取数据时的对象,同步的意思是让kernel buffer和app buffer数据同步*** 。在保持kernel buffer和app buffer同步的过程中,CPU将从执行read()操作的进程切换到内核态,内核获取CPU拷贝数据到app buffer,所以执行read()操作的进程在这个同步的阶段中是被阻塞的。**
只有异步IO模型才是异步的,因为它调用的是具有【神力】的异步IO函数(如aio_read()),调用这些函数时会请求内核,当数据已经拷贝到app buffer后,通知进程并执行指定的操作。
需要注意的是,无论是哪种IO模型,在将数据从kernel buffer拷贝到app buffer的这个阶段,都是需要CPU参与的。只不过,同步IO模型和异步IO模型中,CPU参与的方式不一样:
- 同步IO模型中,调用read()的进程会切换到内核,由内核占用CPU来执行数据拷贝,所以原进程在此阶段一直被阻塞
- 异步IO模型中,由内核在后台默默的执行数据拷贝,所以原进程在此阶段不被阻塞
如图:
2.7 信号驱动IO和异步IO的区别¶
很多人都不理解信号驱动IO和异步IO之间的区别,一方面是因为它们都立即返回,另一方面是因为它们看似都是被动的或后台的。
但其实在前文已经分析清楚了它们的区别,这里仅做总结性分析。在此之前,还是借用前文使用过的类比。
信号驱动IO模型:小姐姐在逛街,小姐姐本没有想过要买什么东西,但如果发现有合适的,也会去买下来,在逛了一段时间后,一件超短裙闪现到小姐姐的视线,小姐姐很喜欢这个款式,于是立即决定买下来,买的时候小姐姐不能再干其它事情。
异步IO模型:小姐姐在逛街,她这次带上了男朋友,只要想买东西,都可以让男朋友去帮忙买,而小姐姐可以继续自己逛自己的,男朋友买好后通知小姐姐即可。
2.7.1 异步IO¶
异步IO通过调用具有异步IO能力的函数来实现。在调用异步函数时,要求指定IO完成时的通知方式。
当IO完成后,内核(这里的内核是广义的,不再局限于操作系统内核,它也可以是浏览器内核,或语言的解释器,或语言的虚拟机)要么通知进程,要么执行回调函数。
这里所谓的IO完成,表示的是已经保持了两边数据的同步(比如kernel buffer和app buffer之间)。而异步之所以称为异步,就体现在完成两边数据同步的阶段中,它表示由内核在后台默默完成数据的同步任务。
对于异步IO来说,它不在乎什么类型的文件描述符,socket、pipe、fifo、terminal以及普通文件都可以执行异步IO。
2.7.2 信号驱动IO¶
信号驱动IO是同步IO模型。
当某个文件描述符设置了O_ASYNC标记时(前文说过,称呼为O_ASYNC是历史原因),表示该文件描述符开启信号驱动IO的功能。
使用信号驱动IO,要求进程注册SIGIO的信号处理程序,注册之后,进程就可以做其他任务。
当有另一端向该描述符写入数据时,就意味着该文件描述符已经就绪,内核会发送SIGIO信号给进程,于是进程会去执行已经注册的SIGIO信号处理程序。一般来说,信号处理程序中,要么是read()类的读取函数,要么是为后面是否读取做判断的变量标记。
但是,内核发送SIGIO信号只是通知进程数据已经就绪,但就绪了多少数据量,进程并不知道。
而且,进程因为收到通知而认为可以数据已就绪,于是执行read(),进程在执行read()的时候,CPU将从用户态切换到内核态,由内核获取CPU来执行数据同步操作,所以在这个阶段中,进程的read()是被阻塞的。
因为信号驱动要求有另一端主动写入数据,所以socket、pipe、fifo、terminal等文件描述符类型是可以信号驱动IO 的,但是不支持对普通文件使用信号驱动IO。
3.select()、poll()和epoll¶
前面说了,这三个函数是文件描述符状态监控的函数,它们可以监控一系列文件的一系列事件,当出现满足条件的事件后,就认为是就绪或者错误。事件大致分为3类:可读事件、可写事件和异常事件。它们通常都放在循环结构中进行循环监控。
select()和poll()函数处理方式的本质类似,只不过poll()稍微先进一点,而epoll处理方式就比这两个函数先进多了。当然,就算是先进分子,在某些情况下性能也不一定就比老家伙们强。
3.1 select() & poll()¶
首先,通过FD_SET宏函数创建待监控的描述符集合,并将此描述符集合作为select()函数的参数,可以在指定select()函数阻塞时间间隔,于是select()就创建了一个监控对象。
除了普通文件描述符,还可以监控套接字,因为套接字也是文件,所以select()也可以监控套接字文件描述符,例如recv buffer中是否收到了数据,也即监控套接字的可读性,send buffer中是否满了,也即监控套接字的可写性。select()默认最大可监控1024个文件描述符。而poll()则没有此限制。
select()的时间间隔参数分3种: (1).设置为指定时间间隔内阻塞,除非之前有就绪事件发生。 (2).设置为永久阻塞,除非有就绪事件发生。 (3).设置为完全不阻塞,即立即返回。但因为select()通常在循环结构中,所以这是轮询监控的方式。
当创建了监控对象后,由内核监控这些描述符集合,于此同时调用select()的进程被阻塞(或轮询)。当监控到满足就绪条件时(监控事件发生),select()将被唤醒(或暂停轮询),于是select()返回满足就绪条件的描述符数量 ,之所以是数量而不仅仅是一个,是因为多个文件描述符可能在同一时间满足就绪条件。由于只是返回数量,并没有返回哪一个或哪几个文件描述符,所以通常在使用select()之后,还会在循环结构中的if语句中使用宏函数FD_ISSET进行遍历,直到找出所有的满足就绪条件的描述符。最后将描述符集合通过指定函数拷贝回用户空间,以便被进程处理。
监听描述符集合的大致过程如下图所示,其中select()只是其中的一个环节:
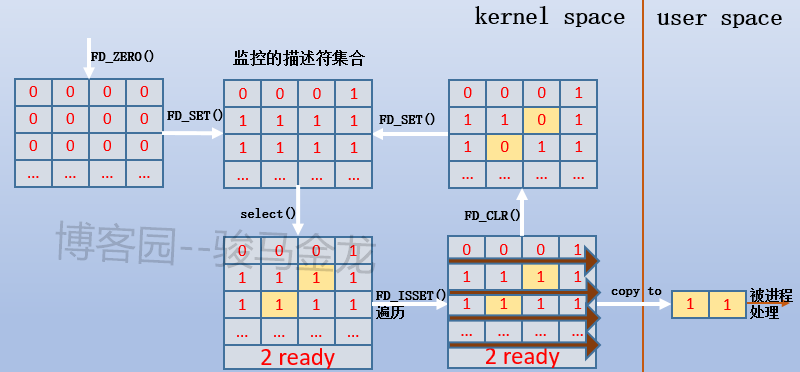
大概描述下这个循环监控的过程:
(1).首先通过FD_ZERO宏函数初始化描述符集合。图中每个小方格表示一个文件描述符。 (2).通过FD_SET宏函数创建描述符集合,此时集合中的文件描述符都被打开,也就是稍后要被select()监控的对象。 (3).使用select()函数监控描述符集合。当某个文件描述符满足就绪条件时,select()函数返回集合中满足条件的数量。图中标黄色的小方块表示满足就绪条件的描述符。 (4).通过FD_ISSET宏函数遍历整个描述符集合,并将满足就绪条件的描述符发送给进程。同时,使用FD_CLR宏函数将满足就绪条件的描述符从集合中移除。 (5).进入下一个循环,继续使用FD_SET宏函数向描述符集合中添加新的待监控描述符。然后重复(3)、(4)两个步骤。
如果使用简单的伪代码来描述:
以上所说只是一种需要循环监控的示例,具体如何做却是不一定的。不过从中也能看出这一系列的流程。
3.2 epoll¶
epoll比poll()、select()先进,考虑以下几点,自然能看出它的优势所在:
(1).epoll_create()创建的epoll实例可以随时通过epoll_ctl()来新增和删除感兴趣的文件描述符,不用再和select()每个循环后都要使用FD_SET更新描述符集合的数据结构。 (2).在epoll_create()创建epoll实例时,还创建了一个epoll就绪链表list。而epoll_ctl()每次向epoll实例添加描述符时,还会注册该描述符的回调函数。当epoll实例中的描述符满足就绪条件时将触发回调函数,被移入到就绪链表list中。 (3).当调用epoll_wait()进行监控时,它只需确定就绪链表中是否有数据即可,如果有,将复制到用户空间以被进程处理,如果没有,它将被阻塞。当然,如果监控的对象设置为非阻塞模式,它将不会被阻塞,而是不断地去检查。
也就是说,epoll的处理方式中,根本就无需遍历描述符集合。